Automating Amazon Book Data Pipelines with Apache Airflow and MySQL
In our previous tutorial, we simulated market data pipelines to explore the full ETL lifecycle in Apache Airflow, from extracting and transforming data to loading it into a local database. Along the way, we integrated Git-based DAG management, automated validation through GitHub Actions, and synchronized our Airflow environment using git-sync, creating a workflow that closely mirrored real production setups.
Now, we’re taking things a step further by moving from simulated data to a real-world use case.
Imagine you’ve been given the task of finding the best engineering books on Amazon, extracting their titles, authors, prices, and ratings, and organizing all that information into a clean, structured table for analysis. Since Amazon’s listings change frequently, we need an automated workflow to fetch the latest data on a regular schedule. By orchestrating this extraction with Airflow, our pipeline can run every 24 hours, ensuring the dataset always reflects the most recent updates.
In this tutorial, you’ll take your Airflow skills beyond simulation and build a real-world ETL pipeline that extracts engineering book data from Amazon, transforms it with Python, and loads it into MySQL for structured analysis. You’ll orchestrate the process using Airflow’s TaskFlow API and custom operators for clean, modular design, while integrating GitHub Actions for version-controlled CI/CD deployment. To complete the setup, you’ll implement logging and monitoring so every stage, from extraction to loading, is tracked with full visibility and accuracy.
By the end, you’ll have a production-like pattern, an Airflow workflow that not only automates the extraction of Amazon book data but also demonstrates best practices in reliability, maintainability, and DevOps-driven orchestration.
Setting Up the Environment and Designing the ETL Pipeline
Setting Up the Environment
We have seen in our previous tutorial how running Airflow inside Docker provides a clean, portable, and reproducible setup for development. For this project, we’ll follow the same approach.
We’ve prepared a GitHub repository to help you get your environment up and running quickly. It includes the starter files you’ll need for this tutorial.
Begin by cloning the repository:
git clone [email protected]:dataquestio/tutorials.gitThen navigate to the Airflow tutorial directory:
cd airflow-docker-tutorialInside, you’ll find a structure similar to this:
airflow-docker-tutorial/
├── part-one/
├── part-two/
├── amazon-etl/
├── docker-compose.yaml
└── README.mdThe part-one/ and part-two/ folders contain the complete reference files for our previous tutorials, while the amazon-etl/ folder is the workspace for this project, it contains all the DAGs, helper scripts, and configuration files we’ll build in this lesson. You don’t need to modify anything in the reference folders; they’re just there for review and comparison.
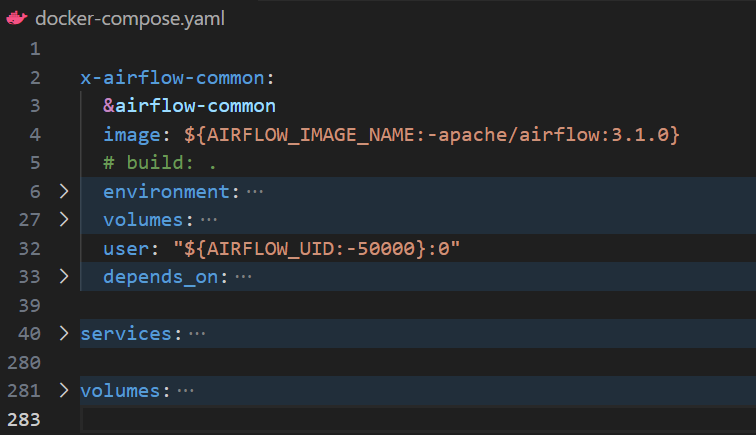
Your starting point is the docker-compose.yaml file, which defines the Airflow services. We’ve already seen how this file manages the Airflow api-server, scheduler, and supporting components.
Next, Airflow expects certain directories to exist before launching. Create them inside the same directory as your docker-compose.yaml file:
mkdir -p ./dags ./logs ./plugins ./configNow, add a .env file in the same directory with the following line:
AIRFLOW_UID=50000This ensures consistent file ownership between your host system and Docker containers.
For Linux users, you can generate this automatically with:
echo -e "AIRFLOW_UID=$(id -u)" > .envFinally, initialize your Airflow metadata database:
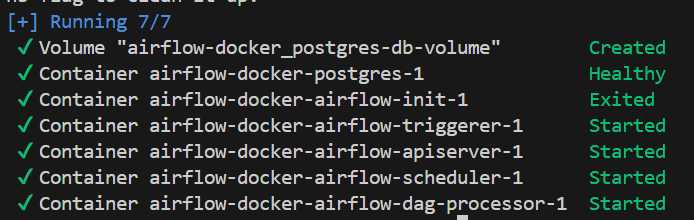
docker compose up airflow-initMake sure your Docker Desktop is already running before executing the command. Once initialization completes, bring up your Airflow environment:
docker compose up -dIf everything is set up correctly, you’ll see all Airflow containers running, including the webserver — which exposes the Airflow UI at http://localhost:8080. Open it in your browser and confirm that your environment is running smoothly by logging in using airflow as the username and airflow as password.
Designing the ETL Pipeline
Now that your environment is ready, it’s time to plan the structure of your ETL workflow before writing any code. Good data engineering practice begins with design, not implementation.
The first step is understanding the data flow, specifically, your source and destination.
In our case:
- The source is Amazon’s public listings for data engineering books.
- The destination is a MySQL database where we’ll store the extracted and transformed data for easy access and analysis.
The workflow will consist of three main stages:
- Extract – Scrape book information (titles, authors, prices, ratings) from Amazon pages.
- Transform – Clean and format the raw text into structured, numeric fields using Python and pandas.
- Load – Insert the processed data into a MySQL table for further use.
At a high level, our data pipeline will look like this:
Amazon Website (Source)
↓
Extract Task
↓
Transform Task
↓
Load Task
↓
MySQL Database (Destination)To prepare data for loading into MySQL, we’ll need to convert scraped HTML into a tabular structure. The transformation step will include tasks like normalizing currency symbols, parsing ratings into numeric values, and ensuring all records are unique before loading.
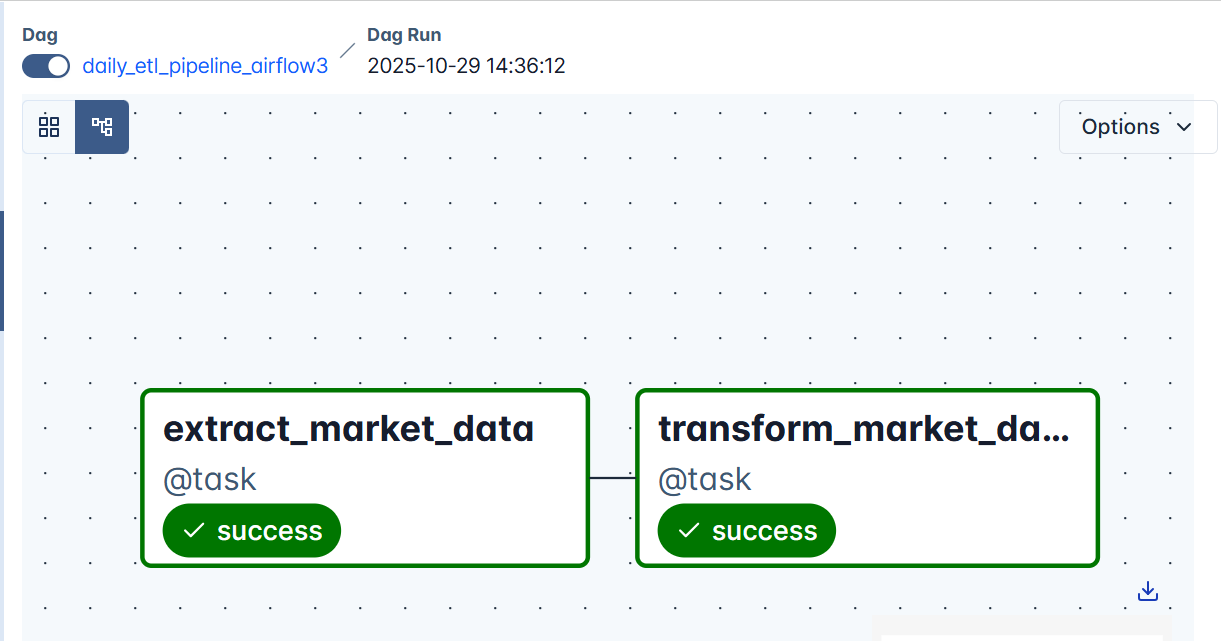
When mapped into Airflow, these steps form a Directed Acyclic Graph (DAG) — a visual and logical representation of our workflow. Each box in the DAG represents a task (extract, transform, or load), and the arrows define their dependencies and execution order.
Here’s a conceptual view of the workflow:
[extract_amazon_books] → [transform_amazon_books] → [load_amazon_books]Finally, we enhance our setup by adding git-sync for automatic DAG updates and GitHub Actions for CI validation, ensuring every change in GitHub reflects instantly in Airflow while your workflows are continuously checked for issues. By combining git-sync, CI checks, and Airflow’s built-in alerting (email or Slack), the entire Amazon ETL pipeline becomes stable, monitored, and much closer to a fully production-like patterns, orchestration system.
Building an ETL Pipeline with Airflow
Setting Up Your DAG File
Let’s start by creating the foundation of our workflow.
Before making changes, make sure to shut down any running containers to avoid conflicts:
docker compose downEnsure that you disable the Example DAGs and switch to LocalExecutor, as we did in our previous tutorials
Now, open your airflow-docker-tutorial project folder and, inside the dags/ directory, create a new file named:
amazon_etl_dag.pyEvery .py file inside this directory becomes a workflow that Airflow automatically detects and manages, no manual registration required. Airflow continuously scans the folder for new DAGs and dynamically loads them.
At the top of your file, import the core libraries needed for this project:
from airflow.decorators import dag, task
from datetime import datetime, timedelta
import pandas as pd
import random
import os
import time
import requests
from bs4 import BeautifulSoupLet’s quickly review what each import does:
dagandtaskcome from Airflow’s TaskFlow API, allowing us to define Python functions that become managed tasks, Airflow handles execution, dependencies, and retries automatically.datetimeandtimedeltahandle scheduling logic, such as when the DAG should start and how often it should run.pandas,random,BeautifulSoup,requests, andosare standard Python libraries we’ll use to process and manage our data within the ETL steps.
This minimal setup is all you need to start orchestrating real-world data workflows.
Defining the DAG Structure
With the imports ready, let’s define the core of our workflow, the DAG configuration.
This determines when, how often, and under what conditions your pipeline runs.
default_args = {
"owner": "Data Engineering Team",
"retries": 3,
"retry_delay": timedelta(minutes=2),
}
@dag(
dag_id="amazon_books_etl_pipeline",
description="Automated ETL pipeline to fetch and load Amazon Data Engineering book data into MySQL",
schedule="@daily",
start_date=datetime(2025, 11, 13),
catchup=False,
default_args=default_args,
tags=["amazon", "etl", "airflow"],
)
def amazon_books_etl():
...
dag = amazon_books_etl()Let’s break down what’s happening here:
default_argsdefine reusable settings for all tasks, in this case, Airflow will automatically retry any failed task up to three times, with a two-minute delay between attempts. This is especially useful since our workflow depends on live web requests to Amazon, which can occasionally fail due to rate limits or connectivity issues.- The
@dagdecorator marks this function as an Airflow DAG. Everything insideamazon_books_etl()will form part of one cohesive workflow. schedule="@daily"ensures our DAG runs once every 24 hours, keeping the dataset fresh.start_datedefines when Airflow starts scheduling runs.catchup=Falseprevents Airflow from trying to backfill missed runs.tagscategorize the DAG in the Airflow UI for easier filtering.
Finally, the line:
dag = amazon_books_etl()instantiates the workflow, making it visible and schedulable within Airflow.
Data Extraction with Airflow
With our DAG structure in place, the first step in our ETL pipeline is data extraction — pulling book data directly from Amazon’s live listings.
- Note that this is for educational purposes: Amazon frequently updates its page structure and uses anti-bot protections, which can break scrapers without warning. In a real production project, we’d rely on official APIs or other stable data sources instead, since they provide consistent data across runs and keep long-term maintenance low.
When you search for something like “data engineering books” on Amazon, the search results page displays listings inside structured HTML containers such as:
<div data-component-type="s-impression-counter">Each of these containers holds nested elements for the book title, author, price, and rating—information we can reliably parse using BeautifulSoup.
For example, when inspecting any of the listed books, we see a consistent HTML structure that guides how our scraper should behave:
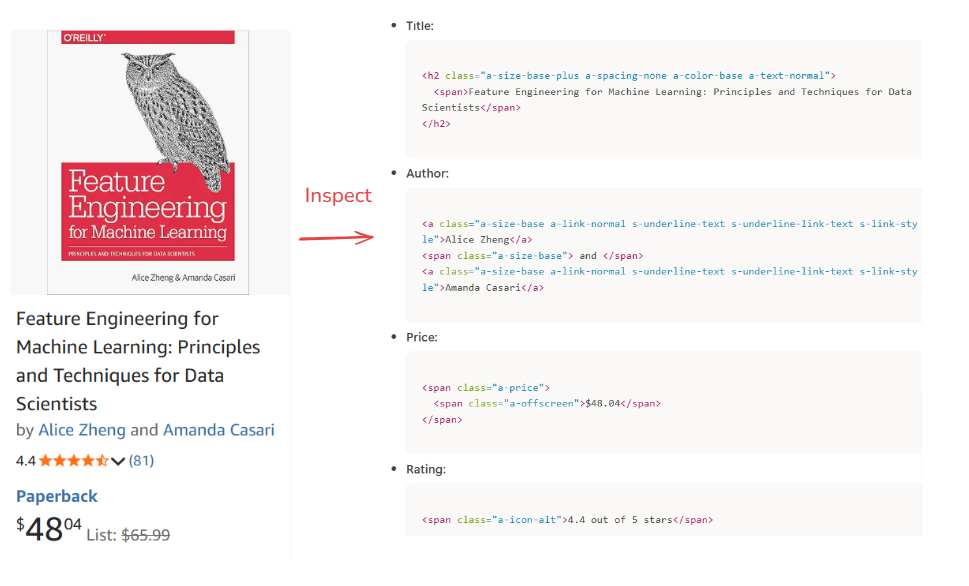
Because Amazon paginates its results, our extraction logic systematically iterates through the first 10 pages, returning approximately 30 to 50 books. We intentionally limit the extraction to this number to keep the workload manageable while still capturing the most relevant items.
This approach ensures we gather the most visible and actively featured books—those trending or recently updated—rather than scraping random or deeply buried results. By looping through these pages, we create a dataset that is both fresh and representative, striking the right balance between completeness and efficiency.
Even though Amazon updates its listings frequently, our Airflow DAG runs every 24 hours, ensuring the extracted data always reflects the latest marketplace activity.
Here’s the Python logic behind the extraction step:
@task
def get_amazon_data_books(num_books=50, max_pages=10, ti=None):
"""
Extracts Amazon Data Engineering book details such as Title, Author, Price, and Rating. Saves the raw extracted data locally and pushes it to XCom for downstream tasks.
"""
headers = {
"Referer": 'https://www.amazon.com/',
"Sec-Ch-Ua": "Not_A Brand",
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": "macOS",
'User-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
base_url = "https://www.amazon.com/s?k=data+engineering+books"
books, seen_titles = [], set()
page = 1 # start with page 1
while page <= max_pages and len(books) < num_books:
url = f"{base_url}&page={page}"
try:
response = requests.get(url, headers=headers, timeout=15)
except requests.RequestException as e:
print(f" Request failed: {e}")
break
if response.status_code != 200:
print(f"Failed to retrieve page {page} (status {response.status_code})")
break
soup = BeautifulSoup(response.text, "html.parser")
book_containers = soup.find_all("div", {"data-component-type": "s-impression-counter"})
for book in book_containers:
title_tag = book.select_one("h2 span")
author_tag = book.select_one("a.a-size-base.a-link-normal")
price_tag = book.select_one("span.a-price > span.a-offscreen")
rating_tag = book.select_one("span.a-icon-alt")
if title_tag and price_tag:
title = title_tag.text.strip()
if title not in seen_titles:
seen_titles.add(title)
books.append({
"Title": title,
"Author": author_tag.text.strip() if author_tag else "N/A",
"Price": price_tag.text.strip(),
"Rating": rating_tag.text.strip() if rating_tag else "N/A"
})
if len(books) >= num_books:
break
page += 1
time.sleep(random.uniform(1.5, 3.0))
# Convert to DataFrame
df = pd.DataFrame(books)
df.drop_duplicates(subset="Title", inplace=True)
# Create directory for raw data.
# Note: This works here because everything runs in one container.
# In real deployments, you'd use shared storage (e.g., S3/GCS) instead.
os.makedirs("/opt/airflow/tmp", exist_ok=True)
raw_path = "/opt/airflow/tmp/amazon_books_raw.csv"
# Save the extracted dataset
df.to_csv(raw_path, index=False)
print(f"[EXTRACT] Amazon book data successfully saved at {raw_path}")
# Push DataFrame path to XCom
import json
summary = {
"rows": len(df),
"columns": list(df.columns),
"sample": df.head(3).to_dict('records'),
}
# Clean up non-breaking spaces and format neatly
formatted_summary = json.dumps(summary, indent=2, ensure_ascii=False).replace('\xa0', ' ')
if ti:
ti.xcom_push(key='df_summary', value= formatted_summary)
print("[XCOM] Pushed JSON summary to XCom.")
# Optional preview
print("\nPreview of Extracted Data:")
print(df.head(5).to_string(index=False))
return raw_pathThis approach makes your pipeline deterministic and meaningful; it doesn’t rely on arbitrary randomness but on a fixed, observable window of recent and visible listings.
You can run this one task and view the logs.

By calling this function, within our def amazon_books_etl() function, we are actually creating a task, and Airflow will consider this as one task:
def amazon_books_etl():
---
# Task dependencies
raw_file = get_amazon_data_books()
dag = amazon_books_etl()You should also notice that we are passing a few pieces of information related to our extracted data to XCOM. These include the total length of our dataframe, the total number of columns, and also the first three rows. This will help us understand the transformation(including cleaning) we need for our data.
Data Transformation with Airflow
Once our raw Amazon book data is extracted and stored, the next step is data transformation — converting the messy, unstructured output into a clean, analysis-ready format.
If we inspect the sample data passed through XCom, it looks something like this:
{
"rows": 42,
"sample": [
{
"Title": "Data Engineering Foundations: Core Techniques for Data Analysis with Pandas, NumPy, and Scikit-Learn (Advanced Data Analysis Series Book 1)",
"Author": "Kindle Edition",
"Price": "$44.90",
"Rating": "4.2 out of 5 stars"
}
],
"columns": ["Title", "Author", "Price", "Rating"]
}We can already notice a few data quality issues:
- The
Pricecolumn includes the dollar sign ($) — we’ll remove it and convert prices to numeric values. - The
Ratingcolumn contains text like"4.2 out of 5 stars"— we’ll extract just the numeric part (4.2). - The
Pricecolumn name isn’t very clear — we’ll rename it toPrice($)for consistency.
Here’s the updated transformation task:
@task
def transform_amazon_books(raw_file: str):
"""
Standardizes the extracted Amazon book dataset for analysis.
- Converts price strings (e.g., '$45.99') into numeric values
- Extracts numeric ratings (e.g., '4.2' from '4.2 out of 5 stars')
- Renames 'Price' to 'Price($)'
- Handles missing or unexpected field formats safely
- Performs light validation after numeric conversion
"""
if not os.path.exists(raw_file):
raise FileNotFoundError(f" Raw file not found: {raw_file}")
df = pd.read_csv(raw_file)
print(f"[TRANSFORM] Loaded {len(df)} records from raw dataset.")
# --- Price cleaning (defensive) ---
if "Price" in df.columns:
df["Price($)"] = (
df["Price"]
.astype(str) # prevents .str on NaN
.str.replace("$", "", regex=False)
.str.replace(",", "", regex=False)
.str.extract(r"(\d+\.?\d*)")[0] # safely extract numbers
)
df["Price($)"] = pd.to_numeric(df["Price($)"], errors="coerce")
else:
print("[TRANSFORM] Missing 'Price' column — filling with None.")
df["Price($)"] = None
# --- Rating cleaning (defensive) ---
if "Rating" in df.columns:
df["Rating"] = (
df["Rating"]
.astype(str)
.str.extract(r"(\d+\.?\d*)")[0]
)
df["Rating"] = pd.to_numeric(df["Rating"], errors="coerce")
else:
print("[TRANSFORM] Missing 'Rating' column — filling with None.")
df["Rating"] = None
# --- Validation: drop rows where BOTH fields failed (optional) ---
df.dropna(subset=["Price($)", "Rating"], how="all", inplace=True)
# --- Drop original Price column (if present) ---
if "Price" in df.columns:
df.drop(columns=["Price"], inplace=True)
# --- Save cleaned dataset ---
transformed_path = raw_file.replace("raw", "transformed")
df.to_csv(transformed_path, index=False)
print(f"[TRANSFORM] Cleaned data saved at {transformed_path}")
print(f"[TRANSFORM] {len(df)} valid records after standardization.")
print(f"[TRANSFORM] Sample cleaned data:\n{df.head(5).to_string(index=False)}")
return transformed_path
This transformation ensures that by the time our data reaches the loading stage (MySQL), it’s tidy, consistent, and ready for querying, for instance, to quickly find the highest-rated or most affordable data engineering books.

- Note: Although we’re working with real Amazon data, this transformation logic is intentionally simplified for the purposes of the tutorial. Amazon’s page structure can change, and real-world pipelines typically include more robust safeguards, such as retries, stronger validation rules, fallback parsing strategies, and alerting, so that temporary layout changes or missing fields don’t break the entire workflow. The defensive checks added here help keep the DAG stable, but a production deployment would apply additional hardening to handle a broader range of real-world variations
Data Loading with Airflow
The final step in our ETL pipeline is data loading, moving our transformed dataset into a structured database where it can be queried, analyzed, and visualized.
At this stage, we’ve already extracted live book listings from Amazon and transformed them into clean, numeric-friendly records. Now we’ll store this data in a MySQL database, ensuring that every 24 hours our dataset refreshes with the latest available titles, authors, prices, and ratings.
We’ll use a local MySQL instance for simplicity, but the same logic applies to cloud-hosted databases like Amazon RDS, Google Cloud SQL, or Azure MySQL.
Before proceeding, make sure MySQL is installed and running locally, with a database and user configured as:
CREATE DATABASE airflow_db;
CREATE USER 'airflow'@'%' IDENTIFIED BY 'airflow';
GRANT ALL PRIVILEGES ON airflow_db.* TO 'airflow'@'%';
FLUSH PRIVILEGES;
When running Airflow in Docker and MySQL locally on Linux, Docker containers can’t automatically access localhost.
To fix this, you need to make your local machine reachable from inside Docker.
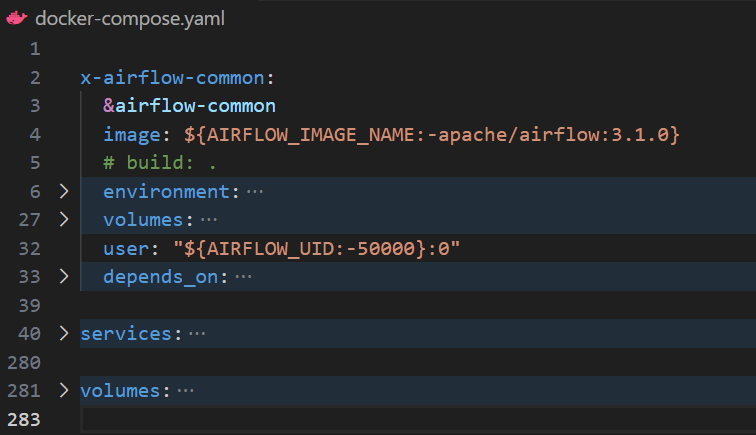
Open your docker-compose.yaml file and add the following line under the x-airflow-common service definition:
extra_hosts:
- "host.docker.internal:host-gateway"
Once configured, we can define our load task:
@task
def load_to_mysql(transformed_file: str):
"""
Loads the transformed Amazon book dataset into a MySQL table for analysis.
Uses a truncate-and-load pattern to keep the table idempotent.
"""
import mysql.connector
import os
import numpy as np
# Note:
# For production-ready projects, database credentials should never be hard-coded.
# Airflow provides a built-in Connection system and can also integrate with
# secret backends (AWS Secrets Manager, Vault, etc.).
#
# Example:
# hook = MySqlHook(mysql_conn_id="my_mysql_conn")
# conn = hook.get_conn()
#
# For this demo, we keep a simple local config:
db_config = {
"host": "host.docker.internal",
"user": "airflow",
"password": "airflow",
"database": "airflow_db",
"port": 3306
}
df = pd.read_csv(transformed_file)
table_name = "amazon_books_data"
# Replace NaN with None (important for MySQL compatibility)
df = df.replace({np.nan: None})
conn = mysql.connector.connect(**db_config)
cursor = conn.cursor()
# Create table if it does not exist
cursor.execute(f"""
CREATE TABLE IF NOT EXISTS {table_name} (
Title VARCHAR(512),
Author VARCHAR(255),
`Price($)` DECIMAL(10,2),
Rating DECIMAL(4,2)
);
""")
# Truncate table for idempotency
cursor.execute(f"TRUNCATE TABLE {table_name};")
# Insert rows
insert_query = f"""
INSERT INTO {table_name} (Title, Author, `Price($)`, Rating)
VALUES (%s, %s, %s, %s)
"""
for _, row in df.iterrows():
try:
cursor.execute(
insert_query,
(row["Title"], row["Author"], row["Price($)"], row["Rating"])
)
except Exception as e:
# For demo purposes we simply skip bad rows.
# In real pipelines, you'd log or send them to a dead-letter table.
print(f"[LOAD] Skipped corrupted row due to error: {e}")
conn.commit()
conn.close()
print(f"[LOAD] Table '{table_name}' refreshed with {len(df)} rows.")
This task reads the cleaned dataset and inserts it into a table named amazon_books_data inside your airflow_db database.

You will also notice that, in the code above that we use a TRUNCATE statement before inserting new rows. This turns the loading step into a full-refresh pattern, making the task idempotent. In other words, running the DAG multiple times produces the same final table instead of accumulating duplicate snapshots from previous days. This is ideal for scraped datasets like Amazon listings, where we want each day’s table to represent only the latest available snapshot.
At this stage, your workflow is fully defined and properly instantiated in Airflow, with each task connected in the correct order to form a complete ETL pipeline. Your DAG structure should now look like this:
def amazon_books_etl():
# Task dependencies
raw_file = get_amazon_data_books()
transformed_file = transform_amazon_books(raw_file)
load_to_mysql(transformed_file)
dag = amazon_books_etl()
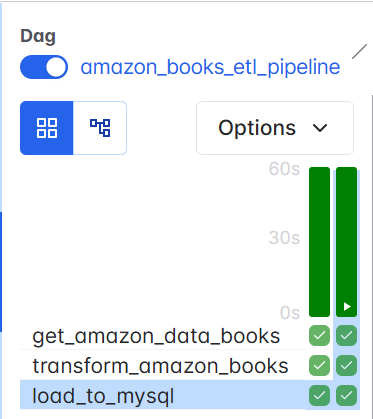
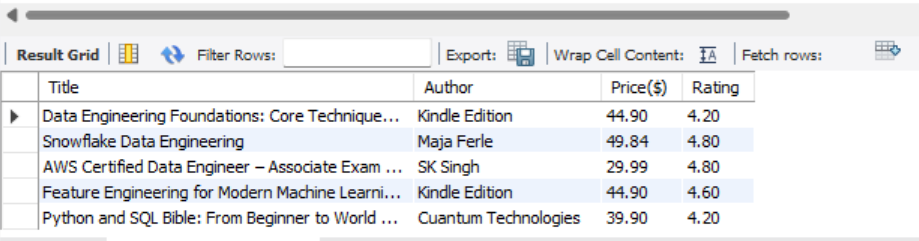
After your DAG runs (use docker compose up -d), you can verify the results inside MySQL:
USE airflow_db;
SHOW TABLES;
SELECT * FROM amazon_books_data LIMIT 5;
Your table should now contain the latest snapshot of data engineering books, automatically updated daily through Airflow’s scheduling system.
If you'd like, I can also show the Airflow Connection UI configuration example or an example using MySqlHook directly instead of mysql.connector.
Adding Git Sync, CI, and Alerts
At this point, you’ve successfully extracted, transformed, and loaded your data. However, your DAGs are still stored locally on your computer, which makes it difficult for collaborators to contribute and puts your entire workflow at risk if your machine fails or gets corrupted.
In this final section, we’ll introduce a few production-like patterns, version control, automated DAG syncing, basic CI checks, and failure alerts. These don’t make the project fully production-ready, but they represent the core practices most data engineers start with when moving beyond local development. The goal here is to show the essential workflow: storing DAGs in Git, syncing them automatically, validating updates before deployment, and receiving notifications when something breaks.
(For a more detailed explanation of the Git Sync setup shown below, you can read the extended breakdown here.)
To begin, create a public or private repository named airflow_dags (e.g., https://github.com/<your-username>/airflow_dags).
Then, in your project root (airflow-docker), initialize Git and push your local dags/ directory:
git init
git remote add origin https://github.com/<your-username>/airflow_dags.git
git add dags/
git commit -m "Add Airflow ETL pipeline DAGs"
git branch -M main
git push -u origin mainOnce complete, your DAGs live safely in GitHub, ready for syncing.
1. Automating Dags with Git Sync
Rather than manually copying DAG files into your Airflow container, we can automate this using git-sync. This lightweight sidecar container continuously clones your GitHub repository into a shared volume.
Each time you push new DAG updates to GitHub, git-sync automatically pulls them into your Airflow environment, no rebuilds, no restarts. This ensures every environment always runs the latest, version-controlled workflow.
As we saw previously, we need to add a new git-sync service to our docker-compose.yaml and create a shared volume called airflow-dags-volume (this can be any name, just make it consistent) that both git-sync and Airflow will use.
services:
git-sync:
image: registry.k8s.io/git-sync/git-sync:v4.1.0
user: "0:0" # run as root so it can create /dags/git-sync
restart: always
environment:
GITSYNC_REPO: "https://github.com/<your-username>/airflow-dags.git"
GITSYNC_BRANCH: "main" # use BRANCH not REF
GITSYNC_PERIOD: "30s"
GITSYNC_DEPTH: "1"
GITSYNC_ROOT: "/dags/git-sync"
GITSYNC_DEST: "repo"
GITSYNC_LINK: "current"
GITSYNC_ONE_TIME: "false"
GITSYNC_ADD_USER: "true"
GITSYNC_CHANGE_PERMISSIONS: "1"
GITSYNC_STALE_WORKTREE_TIMEOUT: "24h"
volumes:
- airflow-dags-volume:/dags
healthcheck:
test: ["CMD-SHELL", "test -L /dags/git-sync/current && test -d /dags/git-sync/current/dags && [ \"$(ls -A /dags/git-sync/current/dags 2>/dev/null)\" ]"]
interval: 10s
timeout: 3s
retries: 10
start_period: 10s
volumes:
airflow-dags-volume:We then replace the original DAGs mount line in the volumes section(- ${AIRFLOW_PROJ_DIR:-.}/dags:/opt/airflow/dags) with - airflow-dags-volume:/opt/airflow/dags so Airflow reads DAGs directly from the synchronized Git volume.
We also set AIRFLOW__CORE__DAGS_FOLDER to /opt/airflow/dags/git-sync/current/dags so Airflow always points to the latest synced repository.
Finally, each Airflow service (airflow-apiserver, airflow-triggerer, airflow-dag-processor, and airflow-scheduler) is updated with a depends_on condition to ensure they only start after git-sync has successfully cloned the DAGs:
git-sync:
condition: service_healthy2. Adding Continuous Integration (CI) with GitHub Actions
To avoid deploying broken DAGs, we can add a lightweight GitHub Actions pipeline that validates DAG syntax before merging into the main branch.
Create a file in your repository:
.github/workflows/validate-dags.yml
name: Validate Airflow DAGs
on:
push:
branches: [ main ]
paths:
- 'dags/**'
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: '3.11'
# Install all required packages for your DAG imports
# (instead of only installing Apache Airflow)
- name: Install dependencies
run: |
pip install -r requirements.txt
# Validate that all DAGs parse correctly
# This imports every DAG file; if any import fails, CI fails.
- name: Validate DAGs
run: |
echo "Validating DAG syntax..."
airflow dags list || exit 1
This workflow automatically runs when new DAGs are pushed, ensuring they parse correctly before reaching Airflow.
3. Setting Up Alerts for Failures
Finally, for real-time visibility, Airflow provides alerting mechanisms that can notify you of any failed tasks via email or Slack.
Add this configuration under your DAG’s default_args:
default_args = {
"owner": "Data Engineering Team",
"email": ["[email protected]"],
"email_on_failure": True,
"retries": 2,
"retry_delay": timedelta(minutes=5),
}If an extraction fails (for instance, Amazon changes its HTML structure or MySQL goes offline), Airflow automatically sends an alert with the error log and task details.
Summary and Up Next
In this tutorial, you built a complete, real-world ETL pipeline in Apache Airflow by moving beyond simulated workflows and extracting live book data from Amazon. You designed a production-style workflow that scrapes, cleans, and loads Amazon listings into MySQL, while organizing your code using Airflow’s TaskFlow API for clarity, modularity, and reliability.
You then strengthened your setup by integrating Git-based DAG management with git-sync, adding GitHub Actions CI to automatically validate workflows, and enabling alerting so failures are detected and surfaced immediately.
Together, these improvements transformed your project into a version-controlled, automated orchestration system that mirrors real production environments and prepares you for cloud deployment.
As a next step, you can expand this workflow by exploring other Amazon categories or by applying the same scraping and ETL techniques to entirely different websites, such as OpenWeather for weather insights or Indeed for job listings. This will broaden your data engineering experience with new, real-world data sources. Running Airflow in the cloud is also an important milestone; this tutorial will help you further deepen your understanding of cloud-based Airflow deployments.