23 Best Python Bootcamps in 2026 – Prices, Duration, Curriculum
Before choosing a Python bootcamp, it helps to understand which programs are actually worth your time and money.
This guide breaks down the best Python bootcamps available in 2026, from affordable self-paced paths to intensive, instructor-led programs and full career-focused bootcamps. You’ll see exactly what each offers, who it’s best for, and what real students say about them.
Since Python is used across many careers, this guide is organized by learning path. This makes it easier to focus on programs that align with your goals, whether you want a general Python foundation or training for a specific role.
Use the jump links below to go straight to the sections that matter most to you and skip anything that doesn’t.
- General Python Bootcamps
- Data Analytics
- Data Science
- Machine Learning & AI
- Software Engineering
- DevOps & Automation
- Web Development
This is your shortcut to choosing a Python bootcamp with confidence, not guesswork.
Best General Python Bootcamps
If you want a structured way to learn, these are some of the best Python-focused bootcamps available today. They offer clear teaching, hands-on projects, and strong support for beginners.
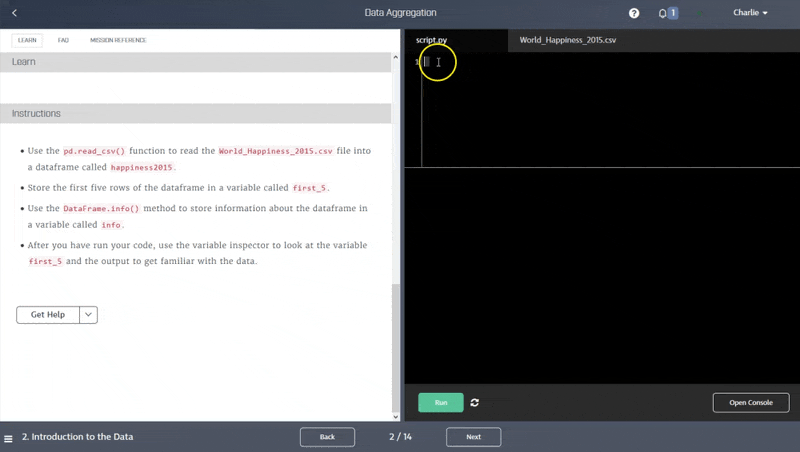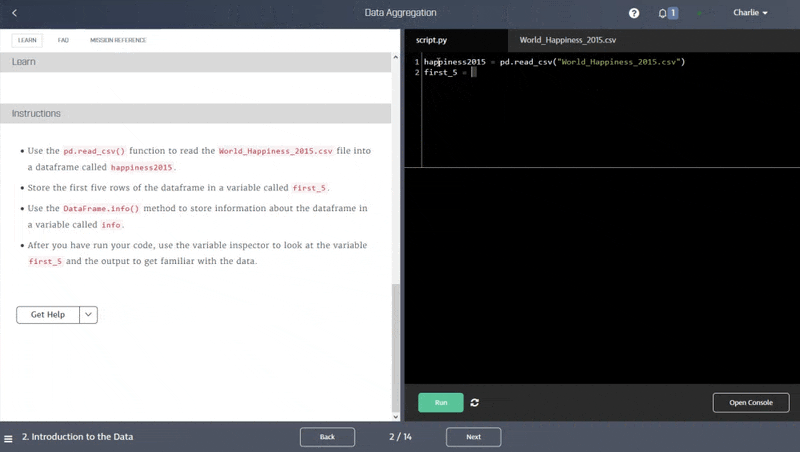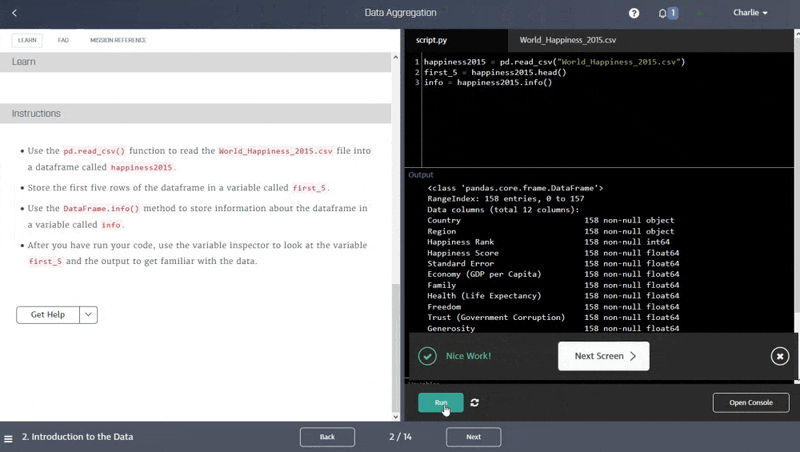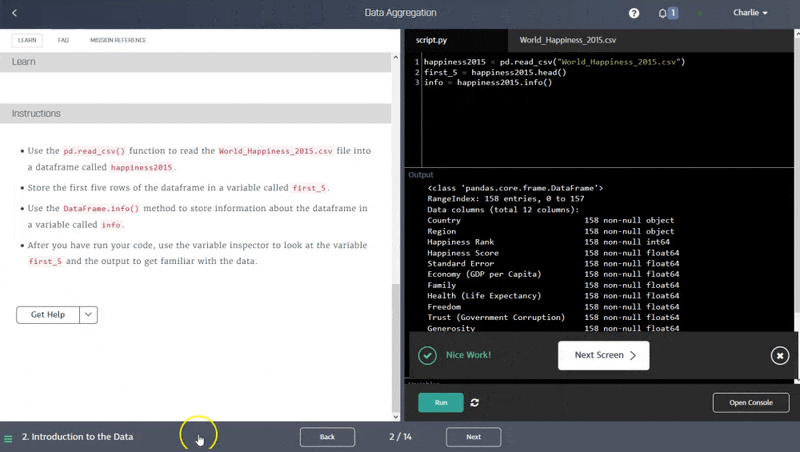
1. Dataquest

- Price: Free to start; full-access plans regularly \$49/month or \$588/year, but often available at a discounted rate.
- Duration: Recommended 5 hrs/week, but completely self-paced.
- Format: Online, self-paced.
- Rating: 4.79/5.
- Extra perks: Browser-based coding, instant feedback, real datasets, guided learning paths, portfolio projects.
- Who it’s best for: Self-motivated learners who want flexible, hands-on coding practice without a huge tuition cost.
Dataquest isn’t a traditional bootcamp, but it’s still one of the most effective ways to learn Python.
Instead of long video lectures, everything is hands-on. You learn by writing real Python code in the browser, completing guided exercises, and building small projects as you go. It’s practical, fast, and far more affordable than most bootcamps without sacrificing results.
One of Dataquest’s biggest strengths is its career paths. These are structured sequences of courses and projects that guide you from beginner to job-ready. You can choose paths in Python such as Data Scientist, Data Analyst, or Data Engineer.
Each path shows you exactly what to learn next and includes real coding projects that help you build a portfolio. This gives you a clear, organized learning experience without the cost or rigidity of a traditional bootcamp.
Dataquest also offers shorter skill paths for more targeted learning. These focus on specific areas like Python fundamentals, machine learning, or APIs and web scraping. They work well if you want to strengthen a particular skill without committing to a full career program.
| Pros | Cons |
|---|---|
| ✅ You learn by doing, every lesson has real coding practice | ❌ No live instructors or cohort-style learning |
| ✅ Much more affordable than most bootcamps | ❌ You need self-discipline since it's fully self-paced |
| ✅ Pick individual courses or follow full learning paths | ❌ Some learners prefer having set deadlines |
| ✅ Projects use real datasets, so you build a portfolio early | ❌ Text-based lessons may not suit video-first learners |
| ✅ Beginner-friendly, with a clear order to follow if you want structure | ❌ No job placement services like some bootcamps offer |
Dataquest starts at the most basic level, so a beginner can understand the concepts. I tried learning to code before, using Codecademy and Coursera. I struggled because I had no background in coding, and I was spending a lot of time Googling. Dataquest helped me actually learn.
― Aaron Melton, Business Analyst at Aditi Consulting
The Dataquest platform offers the necessary elements needed to succeed as a data science learner. By starting from the basics and building upon it, Dataquest makes it easy to grasp and master the concept of data science.
2. Noble Desktop

- Price: \$1,495.
- Duration: 30 hours spread across five intensive days (Monday–Friday, 10 am–5 pm).
- Format: Live online or in person (NYC).
- Rating: 5/5.
- Extra perks: Free retake, class recordings, 1-on-1 mentoring, certificate of completion.
- Who it’s best for: Beginners who prefer live instruction, personal support, and a short, intensive bootcamp.
Noble Desktop has a complete Python bootcamp that is a beginner-friendly program designed for anyone starting from zero.
It covers the essential skills you need for Python-based fields like web development, data science, or automation. Classes are small, hands-on, and taught live by expert instructors.
You’ll learn core programming concepts, including variables, data types, loops, functions, and object-oriented programming. Throughout the week, you’ll complete guided exercises and small projects, ending with code you can upload to GitHub as part of your portfolio.
Students also receive a 1-on-1 training session, access to class recordings, and a free retake within one year.
| Pros | Cons |
|---|---|
| ✅ Very beginner-friendly with clear explanations | ❌ Too basic for learners who already know some Python |
| ✅ Strong instructors with a lot of teaching experience | ❌ Moves quickly, which can feel rushed for absolute beginners |
| ✅ Small class sizes for more personal support | ❌ Only covers fundamentals, not deeper topics |
| ✅ Live online or NYC in-person options | ❌ Higher price for a short program |
| ✅ Free retake and access to class recordings | ❌ Limited career support compared to full bootcamps |
I am learning what I wanted and in the right atmosphere with the right instructor. Art understands Python and knows how to drive its juice into our souls. He is patient and tolerant with us and has so many ways to make each format sink in.
― Jesse Daniels
Very good foundational class with good information for those just starting out in Python. Getting the Python class set up and scheduled was very smooth and the instructor was excellent.
― Clayton Wariner
3. Byte Academy

- Price: Course Report lists the program at about \$14,950 with a \$1,500 refundable deposit, but you need to contact Byte Academy for exact pricing.
- Duration: Full-time or part-time options and hands-on projects + required 4-week internship.
- Format: Live online, instructor-led 45-minute lessons.
- Rating: 3.99/5.
- Extra perks: Mandatory internship, personalized support, real-world project experience.
- Who it’s best for: Aspiring software engineers who want full-stack skills plus Python in a structured, live, project-heavy program.
Byte Academy offers a Python-focused full stack bootcamp with live, instructor-led training and a required internship.
The curriculum covers Python fundamentals, data structures, algorithms, JavaScript, React, SQL, Git, and full end-to-end application development.
Students follow structured lessons, complete daily practice exercises, and build three major projects. These projects include apps that use production databases and external APIs.
A key feature of this bootcamp is the 4-week internship. Students work on real tasks with real deadlines to gain practical experience for their resume. Instructors track progress closely and provide code reviews, interview prep, and presentation practice.
| Pros | Cons |
|---|---|
| ✅ Practical, project-heavy curriculum that helps you build real apps. | ❌ Fast pace can be difficult for beginners without prior coding exposure. |
| ✅ Small classes and instructors who offer close guidance. | ❌ Career support feels inconsistent for some students. |
| ✅ Good option for career changers who need structured learning. | ❌ Job outcomes vary and there's no job guarantee. |
| ✅ Strong focus on Python, full stack skills, and hands-on exercises. | ❌ Requires a heavy weekly time commitment outside of class. |
Coming from a non-coding background, I was concerned about my ability to pick up the coursework but Byte's curriculum is well structured and the staff is so incredibly supportive. I truly felt like I was joining a family and not a bootcamp.
― Chase Ahn
Byte really understands what it takes to get a great job…I can genuinely say that the learning which Byte provided me with, was pinnacle to receiving an offer.
― Ido
4. General Assembly

- Price: \$4,500, with occasional discounts that can reduce tuition to around \$2,700. Installment plans are available, and most learners pay in two to four monthly payments.
- Duration: 10-week part-time (evenings) or 1-week accelerated full-time.
- Format: Live online or in person (depending on region).
- Rating: 4.31/5.
- Extra perks: Capstone project, real-time teaching, AI-related content included.
- Who it’s best for: Beginners who want live instruction, a portfolio project, and flexible part-time or intensive options.
General Assembly’s Python Programming Short Course is built for beginners who want a structured way to learn Python with live, instructor-led classes.
You learn core Python fundamentals and see how they apply to web development and data science. It’s taught by industry professionals and uses a clear, project-based curriculum with around 40 hours of instruction.
The course starts with Python basics, object-oriented programming, and working with common libraries.
Depending on the cohort, the specialization leans toward either data analysis (Pandas, APIs, working with datasets) or web development (Flask, basic backend workflows).
You finish the program by building a portfolio-ready project, such as a small web app or a data analysis tool that pulls from external APIs.
| Pros | Cons |
|---|---|
| ✅ Live, instructor-led classes with real-time support | ❌ Higher cost than most beginner-friendly Python options |
| ✅ Clear, structured curriculum that works well for first-time programmers | ❌ Job support varies and isn't as strong as full bootcamps |
| ✅ Portfolio project lets you showcase real work | ❌ Only 40 hours of instruction, so depth is limited |
| ✅ Flexible schedules (part-time or 1-week intensive) | ❌ Pace can feel fast for complete beginners |
| ✅ Large alumni network and strong brand recognition | ❌ Quality depends on the instructor and cohort |
The approach that the instructor has taken during this course is what I have been looking for in every course that I have been in. General Assembly has acquired some of the finest teachers in the field of programming and development, and if all the other classes are structured the same way as the Python course I took, then there is a very high chance that I will come back for more.
― Nizar Altarooti
The Python course was great! Easy to follow along and the professor was incredibly knowledgeable and skilled at guiding us through the course.
― Fernando
Other Career-Specific Python Bootcamps
Learning Python doesn’t lock you into one job. It’s a flexible skill you can use in data, software, AI, automation, and more. To build a real career, you’ll need more than basic syntax, which is why most bootcamps train you for a full role.
These are the most common career paths you can take with Python and the best programs for each.
Best Python Bootcamps for Data Analytics
Most data analytics bootcamps are more beginner-friendly than data science programs. Python is used mainly for cleaning data, automating workflows, and running basic analysis alongside tools like Excel and SQL.
What you’ll do:
- Work with Excel, SQL, and basic Python
- Build dashboards
- Create reports for business teams
1. Dataquest
- Price: Free to start; \$49/month or \$588/year for full access.
- Duration: ~11 months at 5 hrs/week.
- Format: Online, self-paced.
- Rating: 4.79/5.
- Extra perks: Browser-based coding, instant feedback, real datasets, guided learning paths, portfolio projects.
- Who it’s best for: Beginners who want a fully Python-based, affordable, project-driven path into data science at their own pace.
Dataquest teaches data analytics and data science entirely through hands-on coding.
You learn by writing Python in the browser, practicing with libraries like Pandas, NumPy, Matplotlib, and scikit-learn. Each step builds toward real projects that help you clean data, analyze datasets, and build predictive models.
Because the whole program is structured around Python, it’s one of the easiest ways for beginners to get comfortable writing real code while building a portfolio.
| Pros | Cons |
|---|---|
| ✅ Affordable compared to full bootcamps | ❌ No live mentorship or one-on-one support |
| ✅ Flexible, self-paced structure | ❌ Limited career guidance and networking |
| ✅ Strong hands-on learning with real projects | ❌ Text-based learning, minimal video content |
| ✅ Beginner-friendly and well-structured | ❌ Requires high self-discipline to stay consistent |
| ✅ Covers core tools like Python, SQL, and machine learning |
I used Dataquest since 2019 and I doubled my income in 4 years and became a Data Scientist. That’s pretty cool!
I liked the interactive environment on Dataquest. The material was clear and well organized. I spent more time practicing than watching videos and it made me want to keep learning.
― Jessica Ko, Machine Learning Engineer at Twitter
2. CareerFoundry
- Price: Around \$7,900.
- Duration: 6–10 months.
- Format: Online, self-paced.
- Rating: 4.66/5.
- Extra perks: Dual mentorship model (mentor + tutor), portfolio-based projects, flexible pacing, structured career support.
- Who it’s best for: Complete beginners who want a gentle, guided introduction to Python as part of a broader data analytics skill set, with mentor feedback and portfolio projects.
CareerFoundry includes Python in its curriculum, but it is not the primary focus.
You learn Python basics, data cleaning, and visualization with Pandas and Matplotlib, mostly applied to beginner-friendly analytics tasks. The course also covers Excel and SQL, so Python is one of several tools rather than the main skill.
This bootcamp works well if you want a gradual introduction to Python without jumping straight into advanced programming or machine learning. It’s designed for complete beginners and includes mentor feedback and portfolio projects, but the depth of Python is lighter compared to more technical programs.
| Pros | Cons |
|---|---|
| ✅ Clear structure and portfolio-based learning | ❌ Mentor quality can be inconsistent |
| ✅ Good for beginners switching careers | ❌ Some materials feel outdated |
| ✅ Flexible study pace with steady feedback | ❌ Job guarantee has strict conditions |
| ✅ Supportive community and active alumni | ❌ Occasional slow responses from support team |
The Data Analysis bootcamp offered by CareerFoundry will guide you through all the topics, but lets you learn at your own pace, which is great for people who have a full-time job or for those who want to dedicate 100% to the program. Tutors and Mentors are available either way, and are willing to assist you when needed.
― Jaime Suarez
I have completed the Data Analytics bootcamp and within a month I have secured a new position as data analyst! I believe the course gives you a very solid foundation to build off of.
― Bethany R.
3. Coding Temple

- Price: \$6,000–\$9,000.
- Duration: ~4 months.
- Format: Live online + self-paced.
- Rating: 4.77/5.
- Extra perks: Daily live sessions, LaunchPad real-world projects, smaller class sizes, lifetime career support.
- Who it’s best for: Learners who want a fast-paced, structured program with deeper Python coverage and hands-on analytics and ML practice.
Coding Temple teaches Python more deeply than most data analytics bootcamps.
You work with key libraries like Pandas, NumPy, Matplotlib, and scikit-learn, and you apply them in real datasets through LaunchPad and live workshops. Students also learn introductory machine learning, making the Python portion more advanced than many entry-level programs.
The pace is fast, but you get strong support from instructors and daily live sessions. If you want a structured environment and a clear understanding of how Python is used in analytics and ML, Coding Temple is a good match.
| Pros | Cons |
|---|---|
| ✅ Supportive instructors who explain concepts clearly | ❌ Fast pace can feel intense for beginners |
| ✅ Good mix of live classes and self-paced study | ❌ Job-guarantee terms can be strict |
| ✅ Strong emphasis on real projects and practical tools | ❌ Some topics could use a bit more depth |
| ✅ Helpful career support and interview coaching | ❌ Can be challenging to balance with a full-time job |
| ✅ Smaller class sizes make it easier to get help |
Enrolling in Coding Temple's Data Analytics program was a game-changer for me. The curriculum is not just about the basics; it's a deep dive that equips you with skills that are seriously competitive in the job market.
― Ann C.
The support and guidance I received were beyond anything I expected. Every staff member was encouraging, patient, and always willing to help, no matter how small the question.
― Neha Patel
Best Python Bootcamps for Data Science
Most data science bootcamps use Python as their main language. It’s the standard tool for data analysis, machine learning, and visualization.
What you’ll do in this field:
- Analyze datasets
- Build machine learning models
- Work with statistics, visualization, and cloud tools
- Solve business problems with data
1. BrainStation

- Price: Around \$16,500.
- Duration: 6 months, part-time.
- Format: Live online or in major cities.
- Rating: 4.66/5.
- Extra perks: Live instructor-led classes, real company datasets, career coaching, global alumni network.
- Who it’s best for: Learners who prefer structured, instructor-led programs and real-world data projects.
BrainStation’s Data Science Bootcamp teaches Python from the beginning and uses it for almost every part of the bootcamp.
Students learn Python basics, then apply it to data cleaning, visualization, SQL work, machine learning, and deep learning. The curriculum includes scikit-learn, TensorFlow, and AWS tools, with projects built from real company datasets.
Python is woven throughout the program. So it’s ideal for learners who want structured, instructor-led practice using Python in real data scenarios.
| Pros | Cons |
|---|---|
| ✅ Instructors with strong industry experience | ❌ Expensive compared to similar online bootcamps |
| ✅ Flexible schedule for working professionals | ❌ Fast-paced, can be challenging to keep up |
| ✅ Practical, project-based learning with real company data | ❌ Some topics are covered briefly without much depth |
| ✅ 1-on-1 career support with resume and interview prep | ❌ Career support is not always highly personalized |
| ✅ Modern curriculum including AI, ML, and big data | ❌ Requires strong time management and prior technical comfort |
Having now worked as a data scientist in industry for a few months, I can really appreciate how well the course content was aligned with the skills required on the job.
― Joseph Myers
BrainStation was definitely helpful for my career, because it enabled me to get jobs that I would not have been competitive for before.
― Samit Watve, Principal Bioinformatics Scientist at Roche
2. NYC Data Science Academy

- Price: \$17,600.
- Duration: 12–16 weeks full-time or 24 weeks part-time.
- Format: Live online, in-person (NYC), or self-paced.
- Rating: 4.86/5.
- Extra perks: Company capstone projects, highly technical curriculum, small cohorts, lifelong alumni access.
- Who it’s best for: Students aiming for highly technical Python and ML experience with multiple real-world projects.
NYC Data Science Academy provides one of the most technical Python learning experiences.
Students work with Python for data wrangling, visualization, statistical modeling, and machine learning. The program also teaches deep learning with TensorFlow and Keras, plus NLP tools like spaCy. While the bootcamp includes R, Python is used heavily in the ML and project modules.
With four projects and a real company capstone, students leave with strong Python experience and a portfolio built around real-world datasets.
| Pros | Cons |
|---|---|
| ✅ Teaches both Python and R | ❌ Expensive compared to similar programs |
| ✅ Instructors with real-world experience (many PhD-level) | ❌ Fast-paced and demanding workload |
| ✅ Includes real company projects and capstone | ❌ Requires some technical background to keep up |
| ✅ Strong career services and lifelong alumni access | ❌ Limited in-person location (New York only) |
| ✅ Offers financing and scholarships | ❌ Admission process can be competitive |
The opportunity to network was incredible. You are beginning your data science career having forged strong bonds with 35 other incredibly intelligent and inspiring people who go to work at great companies.
― David Steinmetz, Machine Learning Data Engineer at Capital One
My journey with NYC Data Science Academy began in 2018 when I enrolled in their Data Science and Machine Learning bootcamp. As a Biology PhD looking to transition into Data Science, this bootcamp became a pivotal moment in my career. Within two months of completing the program, I received offers from two different groups at JPMorgan Chase.
― Elsa Amores Vera
3. Le Wagon

- Price: From €7,900.
- Duration: 9 weeks full-time or 24 weeks part-time.
- Format: Online or in-person.
- Rating: 4.95/5.
- Extra perks: Global campus network, intensive project-based learning, AI-focused Python curriculum, career coaching.
- Who it’s best for: Learners who want a fast, intensive program blending Python, ML, and AI skills.
Le Wagon uses Python as the foundation for data science, AI, and machine learning training.
The program covers Python basics, data manipulation with Pandas and NumPy, and modeling with scikit-learn, TensorFlow, and Keras. New modules include LLMs, RAG pipelines, prompt engineering and GenAI tools, all written in Python.
Students complete multiple Python-based projects and an AI capstone, making this bootcamp strong for learners who want a mix of classic ML and modern AI skills.
| Pros | Cons |
|---|---|
| ✅ Supportive, high-energy community that keeps you motivated | ❌ Intense schedule, expect full commitment and long hours |
| ✅ Real-world projects that make a solid portfolio | ❌ Some students felt post-bootcamp job help was inconsistent |
| ✅ Global network and active alumni events in major cities | ❌ Not beginner-friendly, assumes coding and math basics |
| ✅ Teaches both data science and new GenAI topics like LLMs and RAGs | ❌ A few found it pricey for a short program |
| ✅ University tie-ins for MSc or MBA pathways | ❌ Curriculum depth can vary depending on campus |
Looking back, applying for the Le Wagon data science bootcamp after finishing my master at the London School of Economics was one of the best decisions. Especially coming from a non-technical background it is incredible to learn about that many, super relevant data science topics within such a short period of time.
― Ann-Sophie Gernandt
The bootcamp exceeded my expectations by not only equipping me with essential technical skills and introducing me to a wide range of Python libraries I was eager to master, but also by strengthening crucial soft skills that I've come to understand are equally vital when entering this field.
― Son Ma
Best Python Bootcamps for Machine Learning
This is Python at an advanced level: deep learning, NLP, computer vision, and model deployment.
What you’ll do:
- Train ML models
- Build neural networks
- Work with transformers, embeddings, and LLM tools
- Deploy AI systems
1. Springboard

- Price: \$9,900 upfront or \$13,950 with monthly payments; financing and scholarships available.
- Duration: ~9 months.
- Format: Online, self-paced with weekly 1:1 mentorship.
- Rating: 4.6/5.
- Extra perks: Weekly 1:1 mentorship, two-phase capstone with deployment, flexible pacing, job guarantee (terms apply).
- Who it’s best for: Learners who already know Python basics and want guided, project-based training in machine learning and model deployment.
Springboard’s ML Engineering & AI Bootcamp teaches the core skills you need to work with machine learning.
You learn how to build supervised and unsupervised models, work with neural networks, and prepare data through feature engineering. The program also covers common tools such as scikit-learn, TensorFlow, and AWS.
You also build a two-phase capstone project where you develop a working ML or deep learning prototype and then deploy it as an API or web service. Weekly 1:1 mentorship helps you stay on track, get code feedback, and understand industry best practices.
If you want a flexible program that teaches both machine learning and how to put models into production, Springboard is a great fit.
| Pros | Cons |
|---|---|
| ✅ Strong focus on Python for machine learning and AI | ❌ Self-paced format requires strong self-discipline |
| ✅ Weekly 1:1 mentorship for code and project feedback | ❌ Mentor quality can vary between students |
| ✅ Real-world projects, including a deployed capstone | ❌ Program can feel long if you fall behind |
| ✅ Covers in-demand tools like scikit-learn, TensorFlow, and AWS | ❌ Job guarantee has strict requirements |
| ✅ Flexible schedule for working professionals | ❌ Not beginner-friendly without basic Python knowledge |
I had a good time with Spring Board's ML course. The certificate is under the UC San Diego Extension name, which is great. The course itself is overall good, however I do want to point out a few things: It's only as useful as the amount of time you put into it.
― Bill Yu
Springboard's Machine Learning Career Track has been one of the best career decisions I have ever made.
― Joyjit Chowdhury
2. Fullstack Academy

- Price: \$7,995 with discount (regular \$10,995).
- Duration: 26 weeks.
- Format: Live online, part-time.
- Rating: 4.77/5.
- Extra perks: Live instructor-led sessions, multiple hands-on ML projects, portfolio-ready capstone, career coaching support.
- Who it’s best for: Learners who prefer live, instructor-led training and want structured exposure to Python, ML, and AI tools.
Fullstack Academy’s AI & Machine Learning Bootcamp teaches the main skills you need to work with AI.
You learn Python, machine learning models, deep learning, NLP, and popular tools like Keras, TensorFlow, and ChatGPT. The lessons are taught live, and you practice each concept through small exercises and real examples.
You also work on several projects and finish with a capstone where you use AI or ML to solve a real problem. The program includes career support to help you build a strong portfolio and prepare for the job search.
If you want a structured, live learning experience with clear weekly guidance, Fullstack Academy is a good option.
| Pros | Cons |
|---|---|
| ✅ Live, instructor-led classes with clear weekly structure | ❌ Fast pace can be tough without prior Python or math basics |
| ✅ Strong focus on Python, ML, AI, and modern tools | ❌ Fixed class schedule limits flexibility |
| ✅ Multiple hands-on projects plus a portfolio-ready capstone | ❌ Expensive compared to self-paced or online-only options |
| ✅ Good career coaching and job search support | ❌ Instructor quality can vary by cohort |
| ✅ Works well for part-time learners with full-time jobs | ❌ Workload can feel heavy alongside other commitments |
I was really glad how teachers gave you really good advice and really good resources to improve your coding skills.
― Aleeya Garcia
I met so many great people at Full Stack, and I can gladly say that a lot of the peers, my classmates that were at the bootcamp, are my friends now and I was able to connect with them, grow my network of not just young professionals, but a lot of good people. Not to mention the network that I have with my two instructors that were great.
― Juan Pablo Gomez-Pineiro
3. TripleTen

- Price: From \$9,113 upfront (or installments from around \$380/month; financing and money-back guarantee available).
- Duration: 9 months.
- Format: Online, part-time with flexible schedule.
- Rating: 4.84/5.
- Extra perks: Live instructor-led sessions, multiple hands-on ML projects, portfolio-ready capstone, career coaching support.
- Who it’s best for: Beginners who want a flexible schedule, clear explanations, and strong career support while learning advanced Python and ML.
TripleTen’s AI & Machine Learning Bootcamp is designed for beginners, even if you don’t have a STEM background.
You learn Python, statistics, machine learning, neural networks, NLP, and LLMs. The program also teaches industry tools like NumPy, pandas, scikit-learn, PyTorch, TensorFlow, SQL, Docker, and AWS. Training is project-based, and you complete around 15 projects to build a strong portfolio.
You get 1-on-1 tutoring, regular code reviews, and the chance to work on externship-style projects with real companies. TripleTen also offers a job guarantee. If you finish the program and follow the career steps but don’t get a tech job within 10 months, you can get your tuition back.
This bootcamp is a good fit if you want a flexible schedule, beginner-friendly teaching, and strong career support.
| Pros | Cons |
|---|---|
| ✅ Beginner-friendly explanations, even without a STEM background | ❌ Long program length (9 months) can feel slow for some learners |
| ✅ Strong Python focus with ML, NLP, and real projects | ❌ Requires steady self-discipline due to part-time, online format |
| ✅ Many hands-on projects that build a solid portfolio | ❌ Job guarantee has strict requirements |
| ✅ 1-on-1 tutoring and regular code reviews | ❌ Some learners want more live group instruction |
| ✅ Flexible schedule works well alongside a full-time job | ❌ Advanced topics can feel challenging without math basics |
Most of the tutors are practicing data scientists who are already working in the industry. I know one particular tutor, he works at IBM. I’d always send him questions and stuff like that, and he would always reply, and his reviews were insightful.
― Chuks Okoli
I started learning to code for the initial purpose of expanding both my knowledge and skillset in the data realm. I joined TripleTen in particular because after a couple of YouTube ads I decided to look more into the camp to explore what they offered, on top of already looking for a way to make myself more valuable in the market. Immediately, I fell in love with the purpose behind the camp and the potential outcomes it can bring.
― Alphonso Houston
Best Python Bootcamps for Software Engineering
Python is used for backend development, APIs, web apps, scripting, and automation.
What you’ll do:
- Build web apps
- Work with frameworks like Flask or Django
- Write APIs
- Automate tasks
1. Coding Temple
- Price: From \$3,500 upfront with discounts (or installment plans from ~\$250/month; 0% interest options available).
- Duration: ~4–6 months.
- Format: Online, part-time with live sessions.
- Rating: 4.77/5.
- Extra perks: Built-in tech residency, daily live coding sessions, real-world industry projects, and ongoing career coaching.
- Who it’s best for: Learners who want a structured, project-heavy path into full-stack development with Python and real-world coding practice.
Coding Temple has one of the best coding bootcamps that teaches the core skills needed to build full-stack applications.
You learn HTML, CSS, JavaScript, Python, React, SQL, Flask, and cloud tools while working through hands-on projects. The program mixes self-paced lessons with daily live coding sessions, which helps you stay on track and practice new skills right away.
Students also join a built-in tech residency where they solve real coding problems and work on industry-style projects. Career support is included and covers technical interviews, mock assessments, and portfolio building.
It’s a good choice if you want structure, real projects, and a direct path into software engineering.
| Pros | Cons |
|---|---|
| ✅ Very hands-on with daily live coding and frequent practice | ❌ Fast pace can feel overwhelming for complete beginners |
| ✅ Strong focus on real-world projects and applied skills | ❌ Requires a big time commitment outside scheduled sessions |
| ✅ Python is taught in a practical, job-focused way | ❌ Depth can vary depending on instructor or cohort |
| ✅ Built-in tech residency adds realistic coding experience | ❌ Job outcomes depend heavily on personal effort |
| ✅ Ongoing career coaching and interview prep | ❌ Less flexibility compared to fully self-paced programs |
Taking this class was one of the best investments and career decisions I've ever made. I realize first hand that making such an investment can be a scary and nerve racking decision to make but trust me when I say that it will be well worth it in the end! Their curriculum is honestly designed to give you a deep understanding of all the technologies and languages that you'll be using for your career going forward.
― Justin A
My experience at Coding Temple has been nothing short of transformative. As a graduate of their Full-Stack Developer program, I can confidently say this bootcamp delivers on its promise of preparing students for immediate job readiness in the tech industry.
― Austin Carlson
2. General Assembly
- Price: \$16,450 total (installments and 0% interest loan options available).
- Duration: 12 weeks full-time or 32 weeks part-time.
- Format: Online or on campus, with live instruction.
- Rating: 4.31/5.
- Extra perks: Large global alumni network, multiple portfolio projects, flexible full-time or part-time schedules, dedicated career coaching.
- Who it’s best for: Beginners who want a well-known program with live instruction, strong fundamentals, and a broad full-stack skill set.
General Assembly’s Software Engineering Bootcamp teaches full-stack development from the ground up.
You learn Python, JavaScript, HTML, CSS, React, APIs, databases, Agile workflows, and debugging. The program is beginner-friendly and includes structured lessons, hands-on projects, and support from experienced instructors. Both full-time and part-time formats are available, so you can choose a schedule that fits your lifestyle.
Students build several portfolio projects, including a full-stack capstone, and receive personalized career coaching. This includes technical interview prep, resume help, and job search support.
General Assembly is a good option if you want a well-known bootcamp with strong instruction, flexible schedules, and a large global hiring network.
| Pros | Cons |
|---|---|
| ✅ Well-known brand with a large global alumni network | ❌ Expensive compared to many similar bootcamps |
| ✅ Live, instructor-led classes with structured curriculum | ❌ Pace can feel very fast for true beginners |
| ✅ Broad full-stack coverage, including Python and JavaScript | ❌ Python is not the main focus throughout the program |
| ✅ Multiple portfolio projects, including a capstone | ❌ Instructor quality can vary by cohort or location |
| ✅ Dedicated career coaching and interview prep | ❌ Job outcomes depend heavily on individual effort and market timing |
GA gave me the foundational knowledge and confidence to pursue my career goals. With caring teachers, a supportive community, and up-to-date, challenging curriculum, I felt prepared and motivated to build and improve tech for the next generation.
― Lyn Muldrow
I thoroughly enjoyed my time at GA. With 4 projects within 3 months, these were a good start to having a portfolio upon graduation. Naturally, that depended on your effort and diligence throughout the project duration. The pace was pretty fast with a project week after every two weeks of classes, but that served to stretch my learning capabilities.
― Joey L.
3. Flatiron School

- Price: \$17,500, or as low as \$9,900 with available discounts.
- Duration: 15 weeks full-time or 45 weeks part-time.
- Format: Online, full-time cohort, or flexible part-time.
- Rating: 4.45/5.
- Extra perks: Project at the end of every unit, full software engineering capstone, extended career services access, mentor, and peer support.
- Who it’s best for: Learners who want a highly structured curriculum, clear milestones, and long-term career support while learning Python and full-stack development.
Flatiron School teaches software engineering through a structured, project-focused curriculum.
You learn front-end and back-end development using JavaScript, React, Python, and Flask, plus core engineering skills like debugging, version control, and API development. Each unit ends with a project, and the program includes a full software engineering capstone to help you build a strong portfolio.
Students also get support from mentors, 24/7 learning resources, and access to career services for up to 180 days, which includes resume help, job search guidance, and career talks.
Flatiron is a good fit if you want a beginner-friendly bootcamp with strong structure, clear milestones, and both full-time and part-time options.
| Pros | Cons |
|---|---|
| ✅ Strong, well-structured curriculum with projects after each unit | ❌ Intense workload that can feel overwhelming |
| ✅ Multiple portfolio projects plus a full capstone | ❌ Part-time / flex formats require high self-discipline |
| ✅ Teaches both Python and full-stack development | ❌ Instructor quality can vary by cohort |
| ✅ Good reputation and name recognition with employers | ❌ Not ideal for people who want a slower learning pace |
| ✅ Extended career services and job-search support | ❌ Expensive compared to self-paced or online-only options |
As a former computer science student in college, Flatiron will teach you things I never learned, or even expected to learn, in a coding bootcamp. Upon graduating, I became even more impressed with the overall experience when using the career services.
― Anslie Brant
I had a great experience at Flatiron. I met some really great people in my cohort. The bootcamp is very high pace and requires discipline. The course is not for everyone. I got to work on technical projects and build out a great portfolio. The instructors are knowledgable. I wish I would have enrolled when they rolled out the new curriculum (Python/Flask).
― Matthew L.
Best Python Bootcamps for DevOps & Automation
Python is used for scripting, cloud automation, building internal tools, and managing systems.
What you’ll do:
- Automate workflows
- Write command-line tools
- Work with Docker, CI/CD, AWS, Linux
- Build internal automations for engineering teams
1. TechWorld with Nana

- Price: \$1,795 upfront or 5 × \$379.
- Duration: ~6 months (self-paced).
- Format: Online with 24/7 support.
- Rating: 4.9/5.
- Extra perks: Real-world DevOps projects, DevOps certification, structured learning roadmap, active Discord community.
- Who it’s best for: Self-motivated learners who want to use Python for automation while building practical DevOps skills at a lower cost.
TechWorld with Nana’s DevOps Bootcamp focuses on practical DevOps skills through a structured roadmap.
You learn core tools like Linux, Git, Jenkins, Docker, Kubernetes, AWS, Terraform, Ansible, and Python for automation.
The program includes real-world projects where you build pipelines, deploy to the cloud, and write Python scripts to automate tasks. You also earn a DevOps certification and get access to study guides and an active Discord community.
This bootcamp is ideal if you want an affordable, project-heavy DevOps program that teaches industry tools and gives you a portfolio you can show employers.
| Pros | Cons |
|---|---|
| ✅ Strong focus on real-world DevOps projects and automation | ❌ Fully self-paced, no live instructor-led classes |
| ✅ Python taught in a practical DevOps and scripting context | ❌ Less suited for absolute beginners with no tech background |
| ✅ Very affordable compared to DevOps bootcamps | ❌ No formal career coaching or job placement services |
| ✅ Clear learning roadmap that's easy to follow | ❌ Requires strong self-motivation and consistency |
| ✅ Active Discord community for support and questions | ❌ Certification is less recognized than major bootcamp brands |
I would like to thank Nana and the team, your DevOps bootcamp allowed me to get a job as a DevOps engineer in Paris while I was living in Ivory Coast, so I traveled to take the job.
― KOKI Jean-David
I have ZERO IT background and needed a course where I can get the training for DevOps Engineering role. While I'm still progressing through this course, I have feel like I have gained so much knowledge in a short amount of time.
― Daniel
2. Zero To Mastery

- Price: \$25/month (billed yearly at \$299) or \$1,299 lifetime.
- Duration: About 5 months.
- Format: Fully online, self-paced, with an active Discord community and career support.
- Rating: 4.9/5.
- Extra perks: Large course library, 30+ hands-on projects, lifetime access option, active Discord, and career guidance.
- Who it’s best for: Budget-conscious learners who want a self-paced, project-heavy DevOps path with strong Python foundations.
Zero To Mastery offers a full DevOps learning path that includes everything from Python basics to Linux, Bash, CI/CD, AWS, Terraform, networking, and system design.
You also get a complete Python developer course, so your programming foundation is stronger than what many DevOps programs provide.
The path is project-heavy, with 14 courses and 30 hands-on projects, plus optional career tasks like polishing your resume and applying to jobs.
If you want a very affordable way to learn DevOps, build a portfolio, and study at your own pace, ZTM is a practical choice.
| Pros | Cons |
|---|---|
| ✅ Extremely affordable compared to most DevOps bootcamps | ❌ Fully self-paced with no live instructor-led classes |
| ✅ Strong Python foundation alongside DevOps tooling | ❌ Can feel overwhelming due to the large amount of content |
| ✅ Very project-heavy with 30+ hands-on projects | ❌ Requires high self-discipline to finish the full path |
| ✅ Lifetime access option adds long-term value | ❌ No formal job guarantee or placement program |
| ✅ Active Discord community and peer support | ❌ Career support is lighter than traditional bootcamps |
Great experience and very informative platform that explains concepts in an easy to understand manner. I plan to use ZTM for the rest of my educational journey and look forward to future courses.
― Berlon Weeks
The videos are well explained, and the teachers are supportive and have a good sense of humor.
― Fernando Aguilar
3. Nucamp

- Price: \$99/month, with up to 25% off through available scholarships.
- Duration: ~16 weeks (part-time, structured weekly schedule).
- Format: Live online with scheduled instruction and weekend sessions.
- Rating: 4.74/5.
- Extra perks: AI-powered learning tools, lifetime content access, nationwide job board, hackathons, LinkedIn Premium.
- Who it’s best for: Learners who want a low-cost, part-time backend-focused path that still covers Python, SQL, DevOps, and cloud deployment.
Nucamp’s backend program teaches the essential skills needed to build and deploy real web applications.
You start with Python fundamentals, data structures, and common algorithms. Then you move into SQL and PostgreSQL, where you learn to design relational databases and connect them to Python applications to build functional backend systems.
The schedule is designed for people with full-time jobs. You study on your own during the week, then attend live instructor-led workshops to review concepts, fix errors, and complete graded assignments.
Career services include resume help, portfolio guidance, LinkedIn Premium access, and a nationwide job board for graduates.
| Pros | Cons |
|---|---|
| ✅ Very affordable compared to most bootcamps. | ❌ Self-paced format can be hard if you need more structure. |
| ✅ Instructors are supportive, and classes stay small. | ❌ Career help isn't consistent across cohorts. |
| ✅ Good hands-on practice with Python, SQL, and DevOps tools. | ❌ Some advanced topics feel a bit surface-level. |
| ✅ Lifetime access to learning materials and the student community. | ❌ Not as intensive as full-time immersive programs. |
As a graduate of the Back-End Bootcamp with Python, SQL, and DevOps, I can confidently say that Nucamp excels in delivering the fundamentals of the main back-end development technologies, making any graduate of the program well-equipped to take on the challenges of an entry-level role in the industry.
― Elodie Rebesque
The instructors at Nucamp were the real deal—smart, patient, always there to help. They made a space where questions were welcome, and we all hustled together to succeed.
― Josh Peterson
Best Python Bootcamps for Web Development
1. Coding Dojo

- Price: \$9,995 for 1 stack; \$13,495 for 2 stacks; \$16,995 for 3 stacks. You can use a \$100 Open House grant, an up to \$750 Advantage Grant, and optional payment plans.
- Duration: 20-32 weeks, depending on pace.
- Format: Online or on-campus in select cities.
- Rating: 4.38/5.
- Extra perks: Multi-stack curriculum, hands-on projects, career support, mentorship, and career prep workshops.
- Who it’s best for: Learners who want exposure to multiple web stacks, including Python, and strong portfolio development.
Coding Dojo’s Software Development Bootcamp is a beginner-friendly full-stack program for learning modern web development.
You start with basic programming concepts, then move into front-end work and back-end development with Python, JavaScript, or another chosen stack. Each stack includes practice with simple frameworks, server logic, and databases so you understand how web apps are built.
You also learn core tools used in real workflows. This includes working with APIs, connecting your projects to a database, and understanding basic server routing. As you move through each stack, you build small features step by step until you can create a full web application on your own.
The program is flexible and supports different learning styles. You get live lectures, office hours, code reviews, and 24/7 access to the platform. A success coach and career services team help you stay on track, build a portfolio, and prepare for your job search without adding stress.
| Pros | Cons |
|---|---|
| ✅ Multi-stack curriculum gives broader web dev skills than most bootcamps | ❌ Career support quality is inconsistent across cohorts |
| ✅ Strong instructor and TA support for beginners | ❌ Some material can feel outdated in places |
| ✅ Clear progression from basics to full applications | ❌ Students often need extra study after graduation to feel job-ready |
| ✅ 24/7 platform access plus live instruction and code reviews | ❌ Higher cost compared to many online alternatives |
My favorite project was doing my final solo project because it showed me that I have what it takes to be a developer and create something from start to finish.
― Alexander G.
Coding Dojo offers an extensive course in building code in multiple languages. They teach you the basics, but then move you through more advanced study, by building actual programs. The curriculum is extensive and the instructors are very helpful, supplemented by TA's who are able to help you find answers on your own.
― Trey-Thomas Beattie
2. App Academy

- Price: \$9,500 upfront; \$400/mo installment plan; or \$14,500 deferred payment option.
- Duration: ~5 months (part-time live track; daily commitment ~40 hrs/week).
- Format: Online or in-person in select cities.
- Rating: 4.65/5.
- Extra perks: Built-in tech residency, AI-enhanced learning, career coaching, and lifetime support.
- Who it’s best for: Highly motivated learners who want an immersive experience and career-focused training with Python web development.
App Academy’s Software Engineering Program is a beginner-friendly full-stack bootcamp that covers the core tools used in modern web development.
You start with HTML, CSS, and JavaScript, then move into front-end development with React and back-end work with Python, Flask, and SQL. The program focuses on practical, hands-on projects so you learn how complete web applications are built.
You also work with tools used in real production environments. This includes API development, server routing, databases, Git workflows, and Docker. The built-in tech residency gives you experience working on real projects in an Agile setting, with code reviews and sprint cycles that help you build a strong, job-ready portfolio.
The bootcamp supports different learning styles with live instruction, on-demand help, code reviews, and 24/7 access to materials. Success managers and career coaches also help you build your resume, improve your portfolio, and get ready for interviews.
| Pros | Cons |
|---|---|
| ✅ Rigorous curriculum that actually builds real engineering skills | ❌ Very time-intensive and demanding; easy to fall behind |
| ✅ Supportive instructors, TAs, and a strong peer community | ❌ Fast pacing can feel overwhelming for beginners |
| ✅ Tech Residency gives real project experience before graduating | ❌ Not a guaranteed path to a job; still requires heavy effort after graduation |
| ✅ Solid career support (resume, portfolio, interview prep) | ❌ High workload expectations (nights/weekends) |
| ✅ Strong overall reviews from alumni across major platforms | ❌ Stressful assessments and cohort pressure for some students |
In a short period of 3 months, I've learnt a great deal of theoretical and practical knowledge. The instructions for the daily projects are very detailed and of high quality. Help is always there when you need it. The curriculum covers diverse aspects of software development and is always taught with a practical focus.
― Donguk Kim
App Academy was a very structured program that I learned a lot from. It keeps you motivated to work hard through having assessments every Monday and practice assessments prior to the main ones. This helps to constantly let you know what you need to do to stay on track.
― Alex Gonzalez
3. Developers Institute
- Price: 23,000 ILS full-time (~\$6,300 USD) and 20,000 ILS part-time (~\$5,500 USD). These are Early Bird prices.
- Duration: 12 weeks full-time; 28 weeks part-time; 30 weeks flex.
- Format: Online, on-campus (Israel, Mexico, Cameroon), or hybrid.
- Rating: 4.94/5.
- Extra perks: Internship opportunities, AI-powered learning platform, hackathons, career coaching, global locations.
- Who it’s best for: Learners who want a Python + JavaScript full-stack path, strong support, and flexible schedule options.
Developers Institute’s Full Stack Coding Bootcamp is a beginner-friendly program that teaches the essential skills used in modern web development.
You start with HTML, CSS, JavaScript, and React, then move on to backend development with Python, Flask, SQL, and basic API work. The curriculum is practical and project-focused. You learn how the front end and back end fit together by building real applications.
You also learn tools used in professional environments, such as Git workflows, databases, and basic server routing. Full-time students can join an internship for real project experience. All learners also get access to DI’s AI-powered platform for instant feedback, code checking, and personalized quizzes.
The program offers multiple pacing options and includes strong career support. You get 1:1 coaching, portfolio guidance, interview prep, and job-matching tools. This makes it a solid option if you want structured training with Python in the backend and a clear path into a junior software or web development role.
| Pros | Cons |
|---|---|
| ✅ Clear, supportive instructors who help when you get stuck. | ❌ The full-time schedule can feel intense. |
| ✅ Lots of hands-on practice and real coding exercises. | ❌ Some lessons require extra self-study to fully understand. |
| ✅ Helpful AI tools for instant feedback and code checking. | ❌ Beginners may struggle during the first weeks. |
| ✅ Internship option that adds real-world experience. | ❌ Quality of experience can vary depending on the cohort. |
You will learn not only main topics but also a lot of additional information which will help you feel confident as a developer and also impress HR!
― Vladlena Sotnikova
I just finished a Data Analyst course in Developers Institute and I am really glad I chose this school. The class are super accurate, we were learning up-to date skills that employers are looking for. All the teachers are extremely patient and have no problem reexplaining you if you did not understand, also after class-time.
― Anaïs Herbillon
Your Next Step
You don't need to pick the "perfect" bootcamp. You need to pick one that matches where you are right now and where you want to go.
If you're still figuring out whether coding is for you, start with something affordable and flexible like Dataquest or Noble Desktop's short course. If you already know you want a career change and need full support, look at programs like BrainStation, Coding Temple, or Le Wagon that include career coaching and real projects.
The bootcamp itself won't get you the job. It gives you structure, skills, and a portfolio. What comes after (building more projects, applying consistently, fixing your resume, practicing interviews) is still on you.
But if you're serious about learning Python and using it professionally, a good bootcamp can save you months of confusion and give you a clear path forward.
Pick one that fits your schedule, your budget, and your goals. Then commit to finishing it.
The rest will follow.
FAQs
Are Python bootcamps worth it?
Bootcamps can work, but they’re not going to magically land you a perfect job. You still need to put in hours outside of class and be accountable.
Bootcamps are worth it if:
- You need structure because you struggle to stay consistent on your own.
- You want career support like mock interviews, portfolio reviews, or job-search coaching.
- You learn faster with deadlines, instructors, and a guided curriculum.
- You prefer hands-on projects instead of reading tutorials in isolation.
Bootcamps are not worth it if:
- You expect a job to be handed to you at the end.
- You’re not ready to study outside class hours (Sometimes 20–40 extra hours per week is normal).
- The tuition is so high that it adds stress instead of motivation.
Bootcamps work best for people who have already tried learning alone and hit a wall.
They give structure, accountability, networking, and a way to skip the confusion of “what do I learn next?” But you still have to do the messy part: debugging, building projects, failing, trying again, and actually understanding the code.
Bootcamps are worth it when they save you time, not when they sell you shortcuts.
Can you learn Python by yourself?
You can learn Python on your own, and a lot of people do. The language is designed to be readable, and there are endless free resources. You can follow tutorials, practice with small exercises, and slowly build confidence without joining a bootcamp.
The challenge usually appears after the basics. People often get stuck when they try to build real projects or decide what to learn next. This is one reason why bootcamps don’t focus on Python alone. Instead, they focus on careers like data science, analytics, or software development. Python is just one part of the larger skill set you need for those jobs.
So learning Python by yourself is completely possible. Bootcamps simply help learners take the next step and build the full stack of skills required for a specific role.
What’s the best way to learn Python?
No one can tell you exactly how you learn. Some people say you don’t need a structured Python course and that python.org is enough. Others swear by building projects from day one. Some prefer learning from a Python book. None of these are wrong. You can choose whichever path fits your learning style, and you can absolutely combine them.
To learn Python well, you should understand a few core things first. These are the Python foundations that make every tutorial, bootcamp, or project much easier:
- Basic programming concepts (variables, loops, conditionals)
- How Python syntax works and why it’s readable
- Data types and data structures (strings, lists, dictionaries, tuples)
- How to write and structure functions
- How to work with files and modules
- How to install and use libraries (like requests, Pandas, Matplotlib)
- How to find and read documentation
Once you’re comfortable with these basics, you can move into whatever direction you want: data analysis, automation, web development, machine learning, or even simple scripting to make your life easier.
How long does it take to learn Python?
Most people learn basic Python in 1 to 3 months. This includes variables, loops, functions, and simple object-oriented programming.
Reaching an intermediate level takes about 3 to 6 months. At this stage, you can use Python libraries and work in Jupyter Notebook.
Becoming job-ready for a role like Python developer, data scientist, or software engineer usually takes 6 to 12 months because you need extra skills such as SQL, data visualization, or machine learning.
Is Python free?
Yes, Python is completely free. You can download it from python.org and install it on any device.
Most Python libraries for data visualization, machine learning, and software development are also free.
You do not need to pay for a Python course to get started. A coding bootcamp or Python bootcamp is helpful only if you want structure or guidance.
Is Python hard to learn?
Python is as easy a programming language can be. The syntax is simple and clear, which helps beginners understand how code works.
Most people find the challenge later, when they move from beginner basics into intermediate Python topics. This is where you need to learn how to work with libraries, build projects, and debug real code. Reaching advanced Python takes even more practice because you start dealing with larger applications, complex data work, or automation.
This is why some people choose coding bootcamps. They give structure and support when you want a clear learning path.